
Notice
Recent Posts
Recent Comments
Link
gyeomii
🕷Data Crawling 2 본문
반응형
매일경제 주식 시세 사이트 크롤링하기

코드
import requests
from bs4 import BeautifulSoup
url = "https://vip.mk.co.kr/newSt/rate/item_all.php"
response = requests.get(url)
if response.status_code == 200:
html = response.content.decode('euc-kr','replace')
soup = BeautifulSoup(html, 'html.parser')
attr1 = {'class' : 'st2', 'width' : '92'}
tds = soup.find_all('td', attrs = attr1)
#attr2 = {'width':'60'}
#price = soup.find_all('td', attrs= attr2)
for idx, td in enumerate(tds):
s_name = td.text
s_price = td.parent.find_all("td")[1].text
s_code = td.a['title']
print(idx, s_code, s_name, s_price)
else :
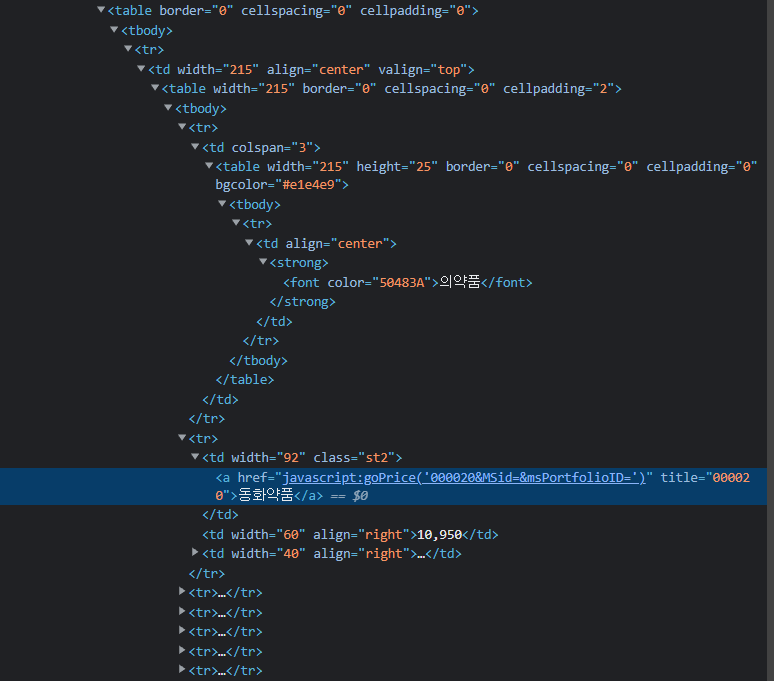
print(response.status_code)- 주식의 이름을 먼저 가져와야 하기 때문에 td중에 class명이 st2인 td를 선택
attr1 = {'class' : 'st2', 'width' : '92'}
tds = soup.find_all('td', attrs = attr1)결과
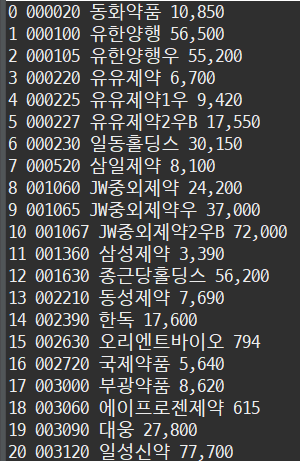
반응형
'개발' 카테고리의 다른 글
| JAVA에서 웹 크롤링하기(1) (0) | 2023.08.29 |
|---|---|
| 🕷Data Crawling 3 (0) | 2023.08.23 |
| 🕷Data Crawling 1 (0) | 2023.08.22 |
| 📈3D Graph2 (0) | 2023.07.27 |
| 📈3D Graph1 (0) | 2023.07.27 |